读心术离我们还有多远?——深圳大学未来媒体技术与计算的最前沿研究
深圳大学未来媒体技术与计算研究所国家特聘专家江健民教授基于近年来在脑视觉感知与认知的研究,开创了一种崭新的脑臆想多媒体研究方向。在全球首次引入“臆想多媒体/Brain Media”的概念和形式,将使传统的多媒体不仅能够呈现人眼所看到的外部世界,同时还能够呈现人脑内部的臆想,包括人们对外来的憧憬,对过去的回忆,以及对人生的感悟等。为实现真正的‘读心术’走出了基于计算机技术的第一步。相关成果近日发表在多媒体领域国际顶级杂志IEEE Transaction on Multimedia上面(全文链接:https://ieeexplore.ieee.org/document/9105088)。 同时于今年以深圳大学为唯一依托单位获得国家基金委信息学部重点项目资助:“臆想多媒体的深度分析与可视呈现”,在2021-2025这五年内将在目前对脑认知图像分类研究的基础上进一步升华到脑认知语义识别的科学研究。为实现基于计算机的读心术及在人工智能环境下开发脑智的最前沿研究准备雄厚的基础。该团队于去年获批建设广东省高校重点实验室:人工智能环境下的脑视觉感知实验室。
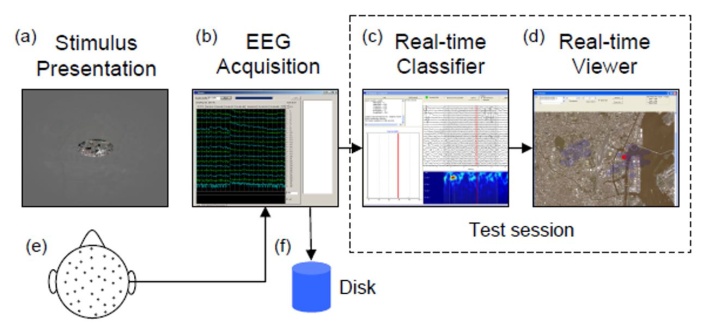
图1

图2
如图1所示,目前的脑科学研究主要采用定向脑激励模式来完成对人脑相关反应的分析。如心理学领域常用的二维选择性模式和脑科学领域常用的数字激励及基于计算机图型的激励模式等。这种现象在人机交互领域涉及人脑的研究也比较普遍,如采用人脑控制机器或动物的行为等研究当中,即使涉及复杂的控制过程但实际的交互仍然是以多级二维选择的方式来实现的。2015年美国斯坦福大学的科研团队在全球率先使用目标图像直接激励人脑的方法(图2),突破了传统的脑科学研究仅采用简单数字或计算机图形激励的模式,完成包含6个类别的脑电图像自动分类研究并取得高达40.68%的准确率。2017年美国佛罗里达大学的科研团队在此基础上直接从ImageNet图像库内提取40个类别的图像用来激励人脑产生相应的脑电信号(EEG)并向全球发布了第一个脑电图像库ImageNet-EEG。在同年计算机视觉及人工智能的顶级学术会议CVPR2017上报告了他们采用深度学习的手段对40个类别的图像脑激励取得了高达82.9%的分类准确率的科研成果(Spampinato C, Palazzo S, Kavasidis I, et al. “Deep Learning Human Mind for Automated Visual Classification”CVPR2017)。2018年美国康奈尔大学的科研团队对此数据库的产生方法提出了质疑,并将相关的实验结果及分析提交到T-PAMI杂志上发表,目前因为存在争议仍在评审中。2019年深圳大学江健民教授团队通过在图像库内的预选图像提取伪脑电信息及其映射的方法,提出一种双模态深度学习框架,将分类的准确率提高到94.1%。之后又利用人脑不同区域对不同激励信息存在敏感差异的特色,提出一种带attention-gate的新型LSTM深度学习方法(图3),将脑图像感知分类进一步提高到98.4%。这意味着你在世界的任一地方看一幅图像,只要将你看这幅图像时的脑信号传到深圳,深圳大学的科研人员就能够以高达98.4%的概率知道你针对这幅图像的脑思维活动并对其内容做具体的可视化呈现(图4)。
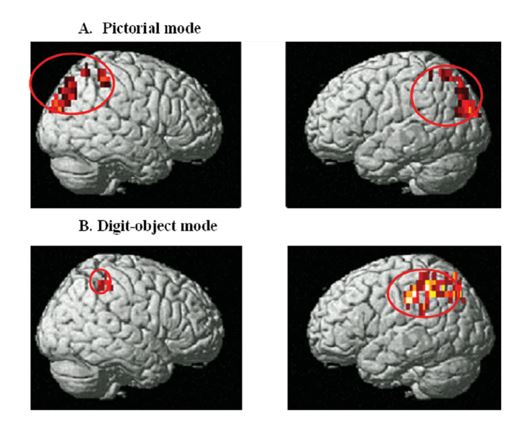
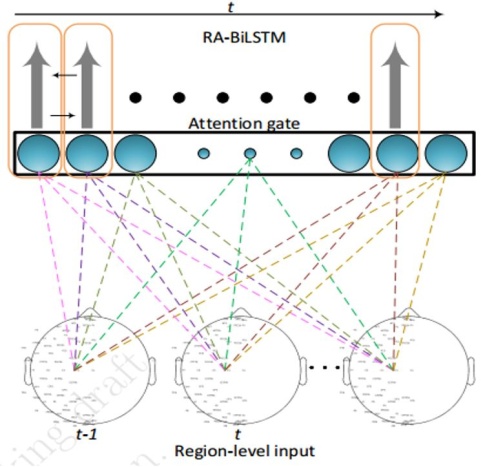
图3
针对人脑思维的不确定性及其脑电信息采集的不稳定性,深圳大学科研团队进一步提出了具有脑特色的深度学习研究,并结合传统的深度学习理论和方法取得了一系列的初步成果。包括能够突破目前深度学习需要大量带标签训练数据瓶颈的跨域学习方法,图像视频内的显著性检测,以及新的三维场景重构模型等。

【免责申明】本专题图片均来源于学校官网或互联网,若有侵权请联系400-0815-589删除。